1. Executor 인터페이스와 구현체

ScheduledExecutorService는 ExecutorService를 확장한 인터페이스이다. 따라서 기본적인 내용은 ExecutorService와 유사한데 스케줄링 실행을 처리하는 몇가지 메소드가 추가되었다. 이 인터페이스를 구현한 대표적인 구현체가 ScheduledThreadPoolExecutor 이다. 결국 ScheduledExecutorService를 이해하기위해서는 Executor인터페이스를 이해해야합니다.
2. Executor인터페이스의 역할
자원은 언제나 제한적이다. 트래픽이 없을때는 아무문제 없지만 엄청난 트래픽이 들어오는데 매 요청마다 스레드를 직접 생성한다면 스레드 생성비용, 스레드간의 문맥교환으로 인해서 문제가 생긴다. 이러한 이유로 스레드풀이 필요해진다. (스레드를 미리 생성하고 풀에서 꺼내쓰고 다쓰면 풀에 반납)
쓰레드풀을 사용한다고 모든 문제가 해결되는것은 아니다. 쓰레드풀이 있더라도 짧은 시간에 엄청난 속도로 트래픽이 몰리면 Thread Pool Hell에 빠질 위험이 있다. (톰캣 기본 쓰레드풀 사이즈가 200인데 쓰레드 200개가 모두 동작하는 과정에서 추가적으로 계속 요청이 들어오면 ready queue에서 대기하고, 대기하는 요청이 큐에서 점점 쌓여가면서 지연시간이 엄청나게 늘어남)
쓰레드를 직접 찍어내는 방식보다는 효율적이기 때문에 쓰레드풀을 사용한다. 이때 Runnable인터페이스를 구현한 Job을 ExecutorService에 넘겨주면 ExecutorService가 Job들을 처리한다. ExecutorService가 일종의 쓰레드풀 역할을 해준다. 즉, Executor는 쓰레드풀 역할을 지원해주는 인터페이스이다.
3. Executor,ExecutorService, ScheduledExecutorService 인터페이스의 차이점
Executor인터페이스를 기반으로 ExecutorService인터페이스,SheduledExecutorService 인터페이스로 확장시킨 구조를 가지고 있다. 각 인터페이스의 특징을 간단하게 알아보자.
1) Executor 인터페이스
개발자가 요청한 일종의 Job을 수행해주는 주체
2) ExecutorService 인터페이스
Executor를 확장한 인터페이스인데 스레드풀을 컨트롤하는 메서드도 제공한다. (shutDown())
3) ScheduledExecutorService 인터페이스
ExecutorService를 확장한 인터페이스인데 Job을 delay시키거나 주기적으로 Job을 수행하게 도와주는 메서드를 제공
4. Executor가 작업을 처리하는 원리
ExecutorService 인터페이스를 구현한 AbstractExecutorService를 상속받은 ThreadPoolExecutor의 execute() 메서드를 확인해보면 아래와 같다. Job(Runnable구현체)를 BlockingQueue에 저장시키고 HashSet에서 워커쓰레드를 꺼내쓰는 방식으로 구현되어있다.
주석으로 execute메서드에서 진행되는 내용을 설명하고 있는데 해석하면 아래와 같다.
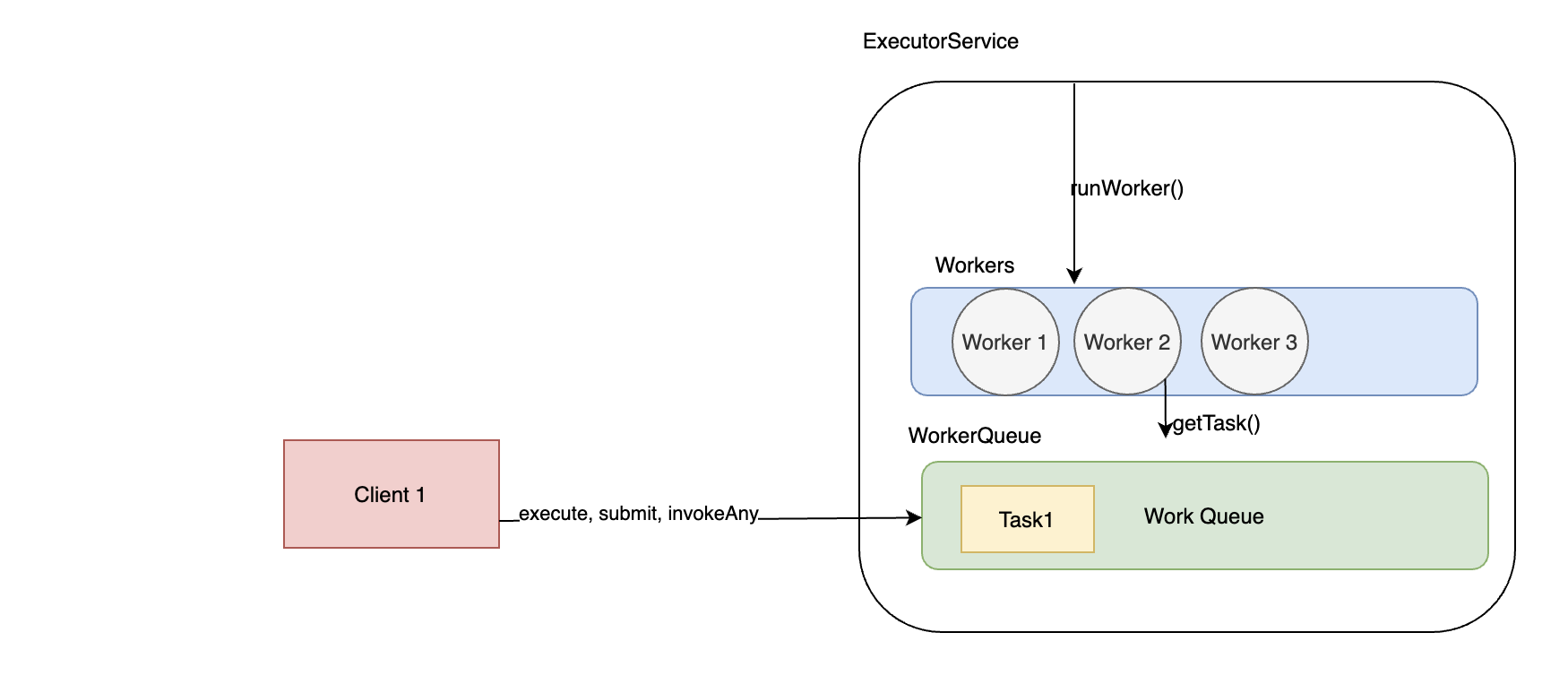
- 인자로 받은 runnable의 null유무를 체크한다.
- worker의 개수가 corePoolSize보다 작으면 새로운 worker 생성하기위해서 addWorker메서드를 호출해서 새로운 worker를 생성한다. 성공한다면 새로운 Worker내부에 들어있는 thread가 시작되도록 thread.run()을 호출한다. (worker내부에는 thread가 있고 이 thread는 workQueue를 지속적으로 확인하면서 새로운 task가 없는지 확인하다가 task를 꺼내서 작업을 시작한다)
- 현재 풀에서 꺼내온 worker가 실행중인지 확인하고 실행중이라면 `worker queue`에 새로운 작업을 등록한다.
- `work queue`에 성공적으로 등록되고나서 바로 스레드의 상태가 shutdown일수도 있으므로 상태를 다시 체크하고 running 상태가 아니라면 reject시키고 함수를 종료한다.
- 4번에서 정상적으로 running상태이지만 worker의 개수가 0이라면 새로운 Worker 생성해서 큐에 넣고 작업을 실행한다.
- 모든 시도를 했지만 worker를 추가하는데 실패했다면 reject처리한다.
결국 Worker라는 Runnable인터페이스를 구현한 구현체를 ExecutorService를 생성할때 할당한 사이즈만큼 계속해서 생성하다가 max값이 되었을때는 더이상 새로운 Worker를 생성하지 않고 계속 재활용하는것이다. 작업은 기본적으로 workQueue라는 곳에 보관시켜두고 Worker의 `getTask()`를 통해서 작업을 꺼내서 계속 실행하는 구조이다.
/**
* The queue used for holding tasks and handing off to worker
* threads. We do not require that workQueue.poll() returning
* null necessarily means that workQueue.isEmpty(), so rely
* solely on isEmpty to see if the queue is empty (which we must
* do for example when deciding whether to transition from
* SHUTDOWN to TIDYING). This accommodates special-purpose
* queues such as DelayQueues for which poll() is allowed to
* return null even if it may later return non-null when delays
* expire.
*/
private final BlockingQueue<Runnable> workQueue;
/**
* Set containing all worker threads in pool. Accessed only when
* holding mainLock.
*/
private final HashSet<Worker> workers = new HashSet<>();
/**
* Executes the given task sometime in the future. The task
* may execute in a new thread or in an existing pooled thread.
*
* If the task cannot be submitted for execution, either because this
* executor has been shutdown or because its capacity has been reached,
* the task is handled by the current {@link RejectedExecutionHandler}.
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
5. Executor인터페이스의 여러가지 구현체별 특징
5.1 ForkJoinPool
하나의 작업을 여러 작읍 단위로 분할하고(fork) 처리한 결과를 합치는(join) 방법이다. Fork Join Pool에서는 RecursiveAction,RecursiveTask인터페이스를 제공하는데 RecursiveAction은 결과를 반환하지 않는 작업이고 RecursiveTask는 결과를 반환하는 작업이다.
스레드 풀에 있는 스데르들은 서로 작업을 하려고 큐에서 작업을 가져가며 각 스레드들은 부모 큐에서 가져간 작업을 내부 큐에 담아서 관리한다. 이때 스레드들은 서로의 큐에 ㅈ버근해서 작업을 가져가 처리할 수 있다. 즉, 놀고 있는 스레드가 없다.
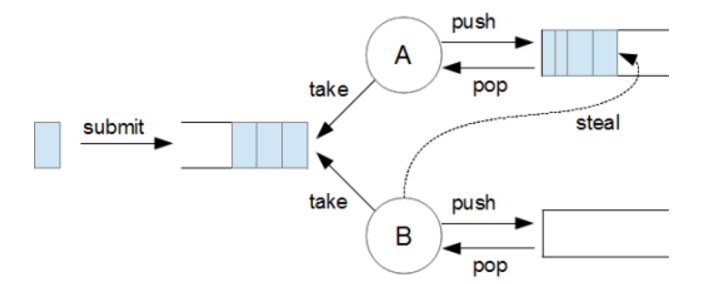
1. 처리해야 하는 작업이 작은가? 작업을 바로 처리
2. 처리할 작업을 두개의 작업으로 쪼갠다. 두개의 작업처리를 호출하고 결과를 기다린다.
128개의 작업을 처리해야할때 128개의 작업을 한개의 쓰레드가 잡으면 한개의 쓰레드 점유시간이 길어지고 나머지 쓰레들은 놀고 있다. ForkJoinPool에서는 작업을 분할해서 다른 쓰레드들이 작업을 꺼내가도록 한다.
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
MyRecursiveAction myRecursiveAction = new MyRecursiveAction(128);
forkJoinPool.invoke(myRecursiveAction);
forkJoinPool.awaitTermination(5, TimeUnit.SECONDS);
public class MyRecursiveAction extends RecursiveAction {
private long workLoad = 0;
public MyRecursiveAction(long workLoad) {
this.workLoad = workLoad;
}
@Override
protected void compute() {
String threadName = Thread.currentThread().getName();
//작업량이 임계치보다 크면 작업을 쪼갠다.
if(this.workLoad > 16) {
System.out.println("[" + LocalTime.now() + "][" + threadName + "]"
+ " Splitting workLoad : " + this.workLoad);
sleep(1000);
List<MyRecursiveAction> subtasks =
new ArrayList<MyRecursiveAction>();
subtasks.addAll(createSubtasks());
for(RecursiveAction subtask : subtasks){
//다른 스레드가 작업을 fork하도록 한다.
subtask.fork();
}
//임계치보다 작으면 스레드가 작업을 수행하도록 한다.
} else {
System.out.println("[" + LocalTime.now() + "][" + threadName + "]"
+ " Doing workLoad myself: " + this.workLoad);
}
}
private List<MyRecursiveAction> createSubtasks() {
List<MyRecursiveAction> subtasks =
new ArrayList<MyRecursiveAction>();
MyRecursiveAction subtask1 = new MyRecursiveAction(this.workLoad / 2);
MyRecursiveAction subtask2 = new MyRecursiveAction(this.workLoad / 2);
subtasks.add(subtask1);
subtasks.add(subtask2);
return subtasks;
}
private void sleep(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
5.2 ThreadPoolExecutor
생성자로 ThreadPoolExecutor를 생성할때는 여러가지 인자가 필요하다.
- corePoolSize
- 관리할 쓰레드 수
- maximumPoolSize
- corePoolSize를 초과하여 최대로 만들 쓰레드 수
- 스레드풀의 corePoolSize만큼의 스레드들이 busy이면 일단 task를 workQueue에 보관시키고 workQueue가 꽉차면 그때서야 maximumPoolSize만큼 스레드를 추가한다. 즉, workQueue의 크기지정을 하지 않고 너무 크게 잡는다면 maximumPoolSize의 값은 아무 효과가 없다.
- keepAliveTime
- corePoolSize를 초과하여 생성된 쓰레드가 있을때 일부 쓰레드들이 idle상태일수가 있다. 이때 idle상태의 쓰레드들의 유지시간을 명시한다.
- workQueue
- 모든 쓰레드가 작업중일때 task를 보관해주고 있는 큐
추가적으로, submit과 execute로 작업을 처리할 수 있는데 submit의 경우 Future를 반환하기때문에 작업결과를 확인할 수 있고 작업간에 예외가 발생하더라도 스레드를 죽이지 않고 그대로 살려둔다 (execute는 스레드를 죽였다가 다시생성) 따라서, 스레드 생성을 위한 오버헤드를 줄일수 있기때문에 submit을 사용하는것이 좋다.
5.3 ScheduledThreadPoolExecutor
ScheduledExecutorService 인터페이스는 ExecutorService를 확장한 인터페이스인데 Job을 delay시키거나 주기적으로 Job을 수행하게 도와주는 메서드를 제공하는 인터페이스이다. 이를 구현한 대표적인 구현체인 ScheduledThreadPoolExecutor는 일정 시간 후, 주기적으로 작업을 실행시키게 해주는 Executor 구현체이다.
- schedule
- 일정 시간 뒤에 job을 실행시키는 메소드이다.
- 인자로 Runnable,delay,TimeUnit을 넘겨서 정해진 시간 후에 작업을 수행하도록 task를 추가한다.
- scheduleAtFixedRate
- 작업을 일정 시간 간격으로 실행시키는 메서드
- 인자로 Runnable,initialDelay,delay,TimeUnit을 넘기는데 initialDelay에 최초에 실행되고 기다리는 시간을 넘겨준다. 그 이후부터는 delay만큼 시간이 지나면 작업을 실행한다. (작업의 종료여부와 상관없이 고정된 delay만큼 반복해서 작업을 수행한다)
- scheduleWithFixedDelay
- scheduleAtFixedRate와 유사하지만 작업의 종료여부에 따라서주기가 변경된다. 즉, 작업이 종료되고나서 delay만큼 시간이 경과하고 다음 작업을 수행한다.
'Java' 카테고리의 다른 글
| Thread Dump로 DeadLock 확인하기 (0) | 2021.06.12 |
|---|---|
| 자바 - enum (0) | 2020.09.01 |
| 자바- Optional (0) | 2020.08.20 |
| 이펙티브 자바 3,4,5장 - 인스턴스화 막기/의존 객체 생성자 주입/ 싱글톤 보장 (0) | 2020.08.06 |
| 인터페이스를 사용하는 이유 (2) | 2020.05.08 |




댓글