카프카

아파치 카프카는 링크드인에서 개발한 `데이터 스트리밍 플랫폼`이다. 카프카에서 등장하는 몇가지 개념을 정리해보자.
카프카에서 사용되는 개념
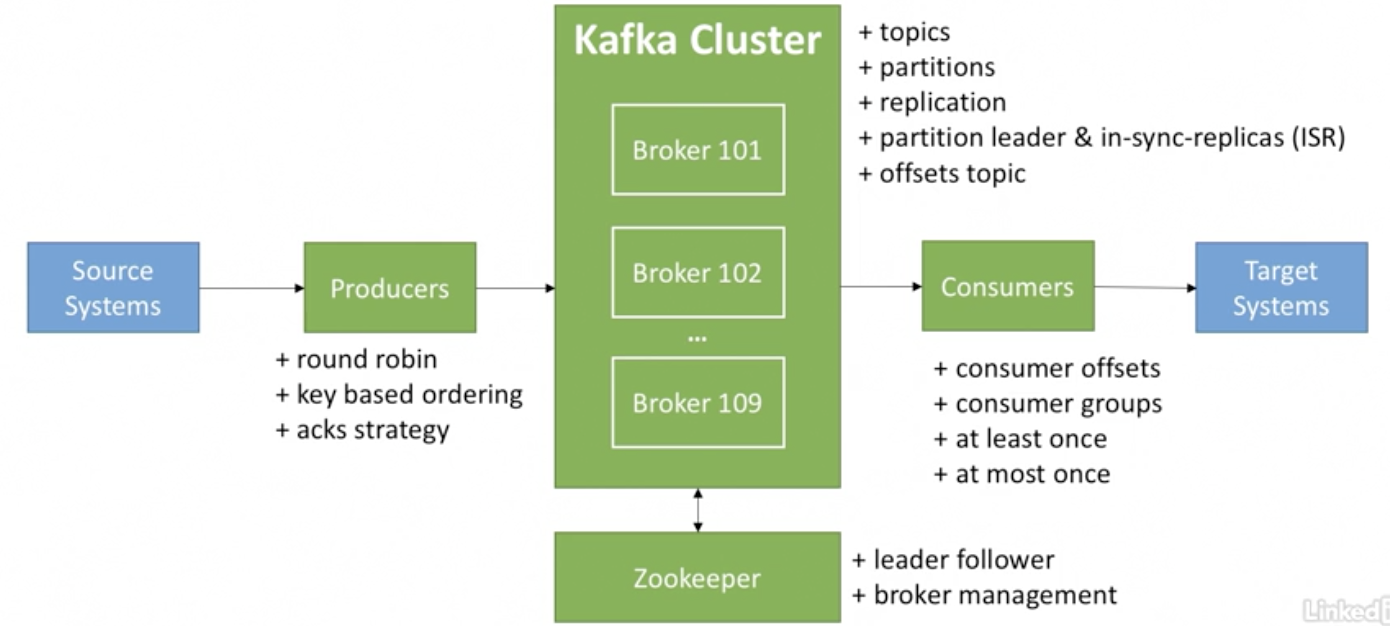
1. 토픽
- 스트리밍 하려는 `특정한 데이터`이다.
- 토픽은 이름으로 식별
- 토픽은 파티션으로 나눠진다.
2. 파티션
- 토픽 내부의 파티션은 독립적이고 파티션 내부에서는 offset이라는 값으로 식별한다.
- 다른 파티션에도 같은 offset이 존재한다
- 파티션 내부에서만 순서가 보장된다.
- 데이터가 파티션에 작성되면 변경될 수 없다.
- 파티션에 저장된 데이터는 제한된 기간동안 유지된다(기본값은 1주일)
3. 브로커
- 브로커는 카프카를 구성하는 서버를 의미한다.
- 카프카 클러스터는 여러개의 브로커로 구성된것을 의미한다.
- 각각의 브로커는 ID로 구분한다.
- 각각의 브로커는 특정 토픽을 포함하고 있다.
- bootstrap 브로커에 연결되면 전체 클러스터와 연결된다.
4. 토픽 복제
- 토픽을 레플리케이션시켜서 다른 브로커가 가지고 있도록 한다.
- `Leadef for a Partition` 한개의 브로커가 파티션에 대해서 리더역할한다. 리더 브로커가 다른 브로커에게 데이터를 동기화시킨다.
- 3개의 브로커로 카프카 클러스터를 구성시키는 경우를 생각해보자
- 1번 브로커가 Topic A의 0번 partition 리더
- 2번 브로커각 Topic A의 1번 partition 리더
- 3번 브로커가 Topic C의 2번 partition리더
- 리더 브로커가 down되더라도 다른 브로커에 데이터가 동기화 되어있기 때문에 고가용성을 보장한다.
5. 프로듀서
- 프로듀서는 데이터를 토픽으로 작성한다.
- acks = 0 : 프로듀서가 ack를 기다리지 않음(데이터 유실 가능성)
- acks = 1 : 리더 브로커가 ack를 넘길때까지 기다린다(데이터 유실가능성 적음)
- acks = all : 리더와 레플리카가 모두 ack를 넘길때까지 기다린다(데이터 유실 없음)
6. 메시지 키
- 프로듀서가 키를 선택해서 메시지를 보낸다.
- key=null이면 라운드 로빈방식으로 보낸다
- key가 있으면 해당 key를 포함하는 모든 메시지는 같은 파티션에 작성
- 순서를 보장해야하는경우에 사용
7. 컨슈머
- 컨슈머는 토픽을 읽는다
- 컨슈머는 어떤 브로커로부터 데이터를 읽어야할지 알고있다.
- 브로커 장애상황에서 컨슈머는 어떻게 복구를해야할지 알고있다.
- 각각의 파티션에 대해서 데이터를 읽는다.
카프카에서의 데이터 보장
프로듀서측에서는 데이터를 생산해서 카프카 클러스터를 통해서 데이터를 스트리밍한다. 컨슈머에서는 토픽을 수신해서 데이터를 소비한다. 컨슈머가 스트리밍으로 넘어온 데이터를 소비할때 어떻게 중복되지 않고 한번만 소비시킬까? 어떻게 모든 데이터를 소비하도록 보장할까? 카프카에서는 아래 세가지 설정이 있다.
- `At most once` : 컨슈머가 메시지를 받자마자 커밋 ( 메시지 유실 가능)
- `At least once` : 컨슈머가 메시지를 받고 처리하고 커밋 ( 처리과정에서 문제가 발생하면 다시 읽음, 중복 발생 가능 하므로 컨트롤 필요)
- `Exactly once` : 정확하게 한번만 consume되는것을 보장하지만 처리속도가 느려진다.
이번에 진행하는 프로젝트에서는 컨슈머에서 중복되는 데이터를 소비하면 안되다. 그리고 대량의 데이터가 많이 몰리기때문에 처리속도또한 중요하다. `At least once`를 선택하고 다른 방법을 통해서 중복을 없애야 한다. 중복 데이터를 없애기 위해서는 어떻게 해야할까? NoSQL을 활용해서 Consumer가 처리하기전에 스트리밍 데이터를 `upsert` 처리함으로써 멱등성을 보장할 수 있다.
댓글